深度学习之CNN,学习网络结构,了解代码实现。卷积神经网络的知识点包括:局部感知、参数共享、池化。
用于图像分类的CNN经典网络有:LeNet5、AlexNet、VGG、GoogleNet、ResNet等,今天我们主要学一下LeNet5结构。
Html语法在Markdown中段落首行缩进的功能,还不错!
理解卷积神经网络,需要先知道的几个概念。
局部感知
- 每个神经元对图像的局部进行感知,然后在更高层将局部信息综合起来得到全局信息。
参数共享
局部连接中隐藏层的每个神经元连接的是一个10×10的局部图像,因此有10×10个权值参数,将这10×10的权值参数共享给剩下的神经元。
可以有效的减少训练参数,加速训练过程。
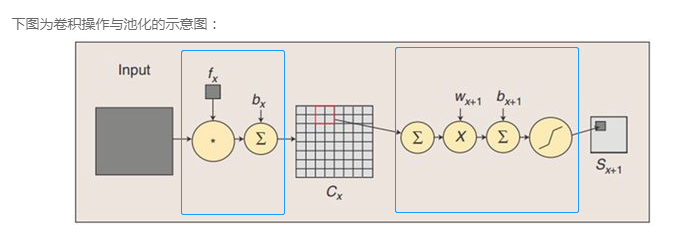
卷积操作又包含以下:
单核单通道卷积
- 通过一个卷积核对一张图像进行卷积,生成一张feature map.
多核单通道卷积
一个卷积核提取的特征不充分。
k个10×10卷积核,对应训练参数为k×10×10(不包含偏置参数).
卷积的过程就是特征提取的过程。
假设对一个1000×1000的图像用k个卷积核10×10做卷积,stride为1,则隐层的节点数量为:k×(1000-100+1)×(1000-100+1).
多核多通道卷积
- 多通道卷积操作通常作用在RGB或者ARGB(A代表透明度)的图像上。
- 对于堆叠卷积层,pooling层之后可以继续接一个卷积层。对池化层的多个Feature Map操作即为多通道卷积。
- 多核说的是卷积核个数,多通道说的是卷积核层数。
- 假设对于ARGB图像,用2个卷积核进行卷积操作。每个卷积核会对应4个卷积模版(各不相同),卷积的Feature Map对应的位置的值是4个卷积模版分别作用在4个通道对应位置处的卷积结果相加然后取激活函数得到的。所以参数的数目为4×2×卷积核的长×卷积核的宽。
池化
- 对卷积后的Feature Map进行池化操作。包括:最大池化,平均池化。
此处疑问:为什么卷积和池化层能起到作用?参考
深度学习正是通过卷积操作实现从细节到抽象的过程。因为卷积的目的就是为了从输入图像中提取特征,并保留像素间的空间关系。何以理解这句话?我们输入的图像其实就是一些纹理,此时,可以将卷积核的参数也理解为纹理,我们目的是使得卷积核的纹理和图像相应位置的纹理尽可能一致。当把图像数据和卷积核的数值放在高维空间中,纹理等价于向量,卷积操作等价于向量的相乘,相乘的结果越大,说明两个向量方向越近,也即卷积核的纹理就更贴近于图像的纹理。因此,卷积后的新图像在具有卷积核纹理的区域信号会更强,其他区域则会较弱。这样,就可以实现从细节(像素点)抽象成更好区分的新特征(纹理)。每一层的卷积都会得到比上一次卷积更易区分的新特征。
而池化目的主要就是为了减少权重参数,但为什么可以以Maxpooling或者MeanPooling代表这个区域的特征呢?这样不会有可能损失了一些重要特征吗?这是因为图像数据在连续区域具有相关性,一般局部区域的像素值差别不大。比如眼睛的局部区域的像素点的值差别并不大,故我们使用Maxpooling或者MeanPooling并不会损失很多特征。
接下来,LeNet网络的结构:
输入层-c1卷积层-s2池化层-c3卷积层-s4池化层-c5卷积层-F6全连接层-输出层

–输入层–
1 张32×32的图片
–C1卷积层–
- 单通道,6个卷积核,得到6个feature maps
- 卷积核大小(kernal size):5×5
- 特征图大小(feature map size):(32-5+1)×(32-5+1)=28×28
- 参数(parameters):6×(5×5+1) 5×5为卷积核模版参数,1为骗纸偏置参数
- 连接(connections):6×(5×5 +1)×28×28
–S2池化层–
- 6个池化核,得到6个feature maps
- kernal size: 2×2
- feature map size: (28/2)×(28/2)=14×14
- parameters:6×(1+1)
- parameters计算过程:2 ×2单元里的值相加然后再乘以训练参数w, 最后加上一个偏置参数b(feature map共享相同的w和b) (跟卷积不太一样这块,之前都是按卷积操作理解的,6 ×(4+1))
- connections:6×(2×2+1)×14×14
–C3卷积层–
- 多核多通道卷积:14个通道,16个卷积核,得到16个feature maps
- kernel size:5×5
- feature map size:(14-5+1)×(14-5+1)=10×10
- parameters:6×(3×5×5+1)+6×(4×5×5+1)+3×(4×5×5+1)+1×(6×5×5+1)
- S2与C3之间不是全连接而是部分连接
- connections:6×(3×5×5+1)+6×(4×5×5+1)+3×(4×5×5+1)+1×(6×5×5+1)×10×10
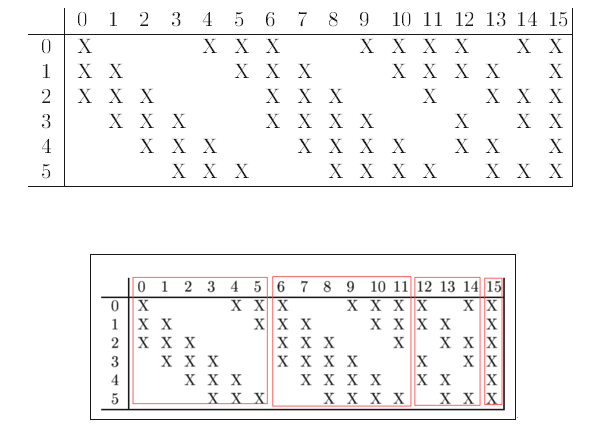
- 此处采用部分连接(Dropout):
- 减少可计算参数
- 打破对称性,这样就能得到输入的不同特征集合
- 从第0个feature map描述计算过程:
- 用一个卷积核(对应3个卷积模板,但仍称为一个卷积核,可以认为是三维卷积核)分别与S2层的3个feature maps进行卷积,然后将卷积的结果相加,再加上一个偏置,再搞个激活函数就可以得出对应的feature map了
–S4池化层–
- 16个池化核,得到16个feature maps
- kernal size:2×2
- feature map size: (10/2)×(10/2)=5×5
- parameters:16×(1+1)
- connections:16×(2×2+1)×5×5
–C5卷积层–
- 120个卷积核,得到120个feature maps
- kernal size:5×5
- 每个feature map的大小都与上一层S4的所有feature maps进行连接,这样一个卷积核就有16个卷积模版。
- feature map size:(5-5+1)×(5-5+1)=1×1,这样刚好变成了全连接,但是我们不把他写成F5,因为这只是巧合。
- parameters:120×(16×5×5+1)
- connections:120×(16×5×5+1)×1×1
–F6全连接层–
- parameters:84×(120×1×1+1)
- connections:84×(120×1×1+1)×1×1
–输出层–
得到分类结果,例:结果为数字几
代码实现:
‘’’ Python
1 | import os |
‘’’
实验结果
step 0,training accuracy 0.12
step 1000,training accuracy 1
step 2000,training accuracy 0.98
step 3000,training accuracy 0.98
step 4000,training accuracy 0.94
step 5000,training accuracy 1
step 6000,training accuracy 1
step 7000,training accuracy 1
step 8000,training accuracy 1
….